It’s not always natural what the “right” behavior is.
-` abcdlsj@Lenovo-13ARE
.o+` --------------------
`ooo/ OS: Arch Linux x86_64
`+oooo: Host: 82DM Lenovo XiaoXinPro-13ARE 2020
`+oooooo: Kernel: 5.11.4-zen1-1-zen
-+oooooo+: Uptime: 1 hour, 54 mins
`/:-:++oooo+: Packages: 1326 (pacman)
`/++++/+++++++: Shell: zsh 5.8
`/++++++++++++++: Resolution: 2560x1600
`/+++ooooooooooooo/` WM: i3
./ooosssso++osssssso+` Theme: Adwaita-dark [GTK2/3]
.oossssso-````/ossssss+` Icons: Papirus-Dark [GTK2/3]
-osssssso. :ssssssso. Terminal: alacritty
:osssssss/ osssso+++. CPU: AMD Ryzen 7 4800U with Radeon Graphics (16) @ 1.800GHz
/ossssssss/ +ssssooo/- GPU: AMD ATI 03:00.0 Renoir
`/ossssso+/:- -:/+osssso+- Memory: 5086MiB / 13912MiB
`+sso+:-` `.-/+oso:
`++:. `-/+/
.` `/
环境搭建以及如何调试
环境用官方的虚拟机或者自己的 Linux 发行版也可以,下载必需的包就可以,官方有写。
调试可以看看 https://blog.csdn.net/kangyupl/article/details/108589594
编译遇到 out_of_range() not found 的问题,添加 #include <stdexcept> 就可以了
Lab 0: networking warmup
https://cs144.github.io/assignments/lab0.pdf
Lab 0 实现有两个任务,webget 和 ByteStreams
webget 实现如下:
TCPSocket sock{};
sock.connect(Address(host, "http"));
string input("GET " + path + " HTTP/1.1\r\nhost: " + host + "\r\n\r\n");
sock.write(input);
sock.shutdown(SHUT_WR);
while (!sock.eof()) {
cout << sock.read();
}
sock.close();
ByteStreams 则是实现一个类似双端队列的东西,我直接使用 std::deque<char> 实现。
这里写下 eof 实现:
bool ByteStream::eof() const { return input_ended() && buffer_empty(); }
eof 代表无法继续从 stream 读出数据,不仅要判断输入完成,还要判断 buffer 已被读完。
Lab 1: stitching substrings into a byte stream
https://cs144.github.io/assignments/lab1.pdf
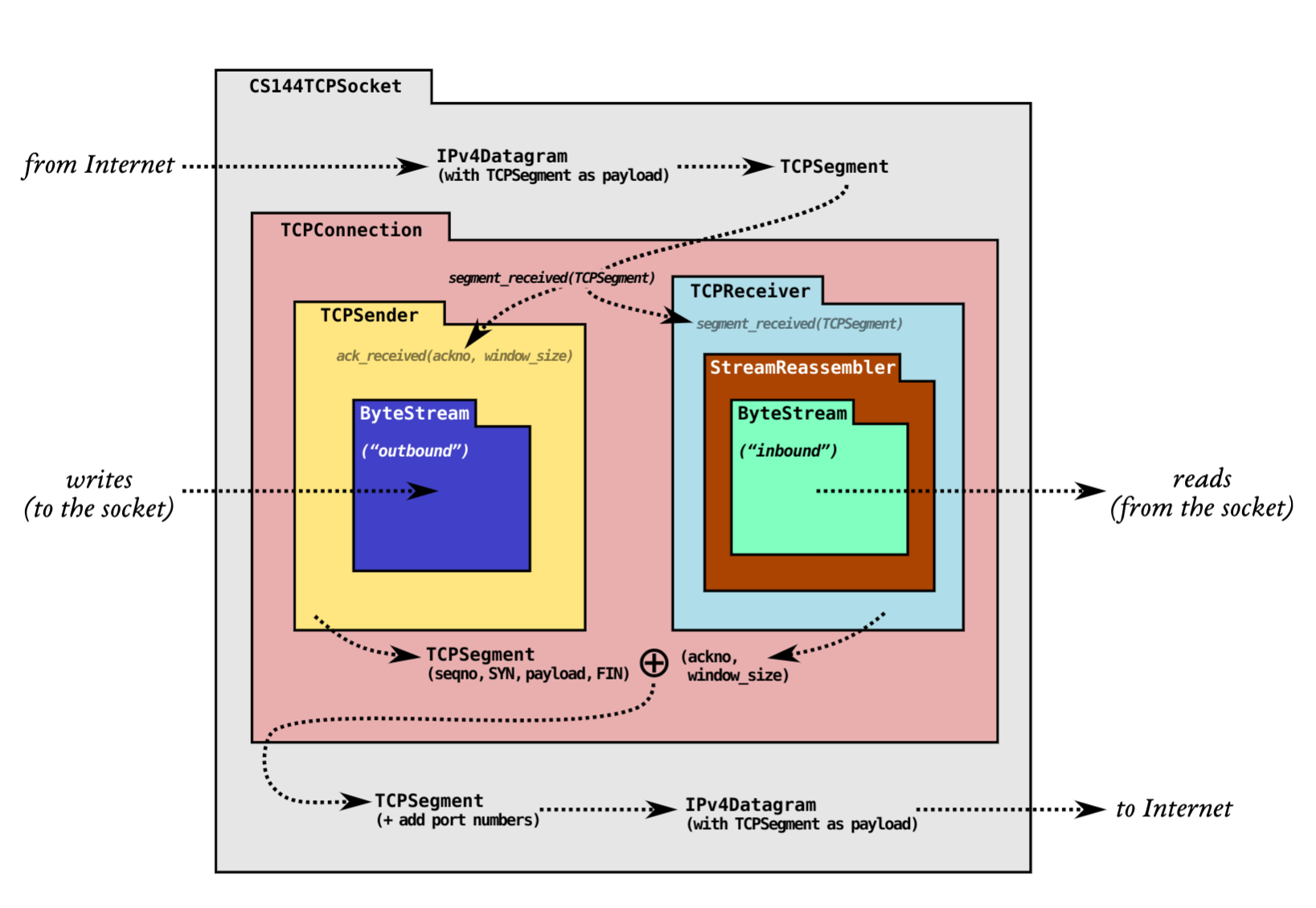
Lab 1 要求实现一个 StreamReassembler,在 Lab 的 TCP 实现图当中(上图)可以看到 TCPReceiver 具有一个 StreamReassembler 用来重组接收到的 Bytes,CS144 目的就是实现一个能够在不可靠数据报传输网络上传输两个 ByteStreams 的 TCP 程序。
实现细节:
从下图可以看到 StreamReassembler 包含 ByteStreams 和未被重组的部分。
关于一些实现的 tips:
-
序号从
0开始,也就是序号和串的长度有关。 -
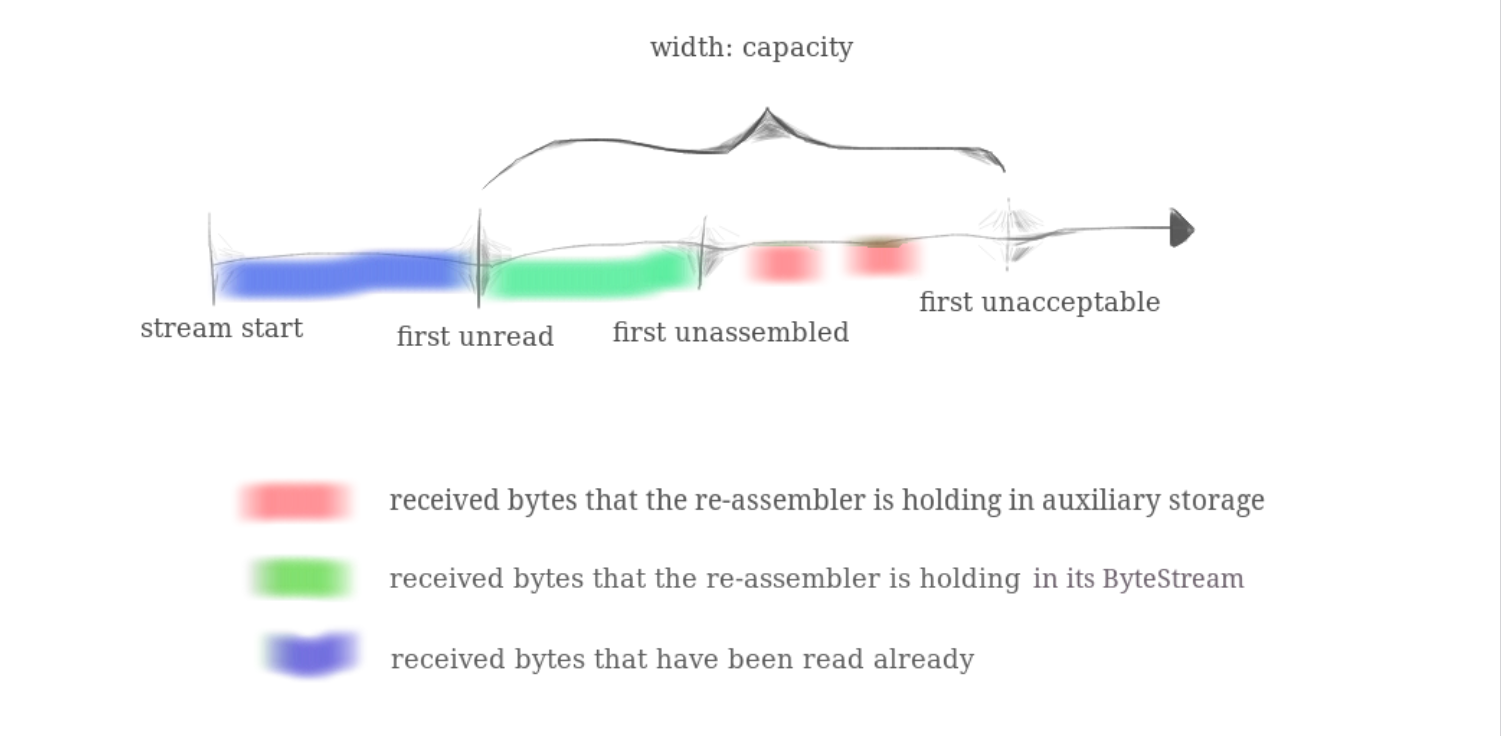
first unread值是什么?因为
StreamReassembler的目的是保存那些无法立即写入到ByteStreams的子串,所有的串最终都会传输到ByteStreams。那么first unread在整个流中的位置其实就是ByteStream中的bytes_read(), 即readed的数据长度。 -
first unassembled值?ByteStream中的bytes_written() -
first unacceptable值是什么?first unread+capacity -
capacity是怎么定义的?根据
PDF,定义为红色部分加上绿色部分,其中绿色是ByteStream的部分,红色代表未被重组的段。
其实很多东西都是围绕下面的图来的。
代码:
这是未重组部分的节点构造,包含一个 index 和 data
struct Segment {
size_t _index;
std::string _data;
Segment(int index, std::string data) : _index(index), _data(data) {}
bool operator<(const Segment &s) const { return this->_index < s._index; }
};
StreamReassembler 结构
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
std::set<Segment> _waiting_buffer;
size_t _unassembled_bytes_size;
bool _flag_eof;
size_t _pos_eof;
#include "stream_reassembler.hh"
#include <cstddef>
#include <pthread.h>
// Dummy implementation of a stream reassembler.
// For Lab 1, please replace with a real implementation that passes the
// automated checks run by `make check_lab1`.
// You will need to add private members to the class declaration in `stream_reassembler.hh`
template <typename... Targs>
void DUMMY_CODE(Targs &&.../* unused */) {}
using namespace std;
StreamReassembler::StreamReassembler(const size_t capacity)
: _output(capacity)
, _capacity(capacity)
, _waiting_buffer({})
, _unassembled_bytes_size(0)
, _flag_eof(false)
, _pos_eof(0) {}
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::insert_buffer(const Segment &s) {
if (_waiting_buffer.empty()) {
_waiting_buffer.insert(s);
_unassembled_bytes_size += s._data.size();
return;
}
Segment c = s;
size_t idx = c._index, sz = c._data.size();
auto it = _waiting_buffer.lower_bound(s);
if (it != _waiting_buffer.begin()) {
it--;
if (it->_index + it->_data.size() > idx) {
if (idx + sz <= it->_index + it->_data.size())
return;
c._data = it->_data + c._data.substr(it->_index + it->_data.size() - idx);
c._index = it->_index;
idx = c._index, sz = c._data.size();
_unassembled_bytes_size -= it->_data.size();
_waiting_buffer.erase(it++);
} else {
it++;
}
}
while (it != _waiting_buffer.end() && idx + sz > it->_index) {
if (idx >= it->_index && idx + sz <= it->_index + it->_data.size())
return;
if (idx + sz < it->_index + it->_data.size()) {
c._data += it->_data.substr(idx + sz - it->_index);
sz = c._data.size();
}
_unassembled_bytes_size -= it->_data.size();
_waiting_buffer.erase(it++);
}
_unassembled_bytes_size += c._data.size();
_waiting_buffer.insert(c);
}
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
auto s = Segment(index, data);
auto first_unread_idx = _output.bytes_read();
auto first_unassembled_idx = _output.bytes_written();
auto first_unacceptable_idx = first_unread_idx + _capacity;
if (index >= first_unacceptable_idx || index + data.size() < first_unassembled_idx)
return;
if (index + data.size() > first_unacceptable_idx) {
s._data = s._data.substr(0, first_unacceptable_idx - index);
}
if (index <= first_unassembled_idx) {
_output.write(s._data.substr(first_unassembled_idx - index));
auto it = _waiting_buffer.begin();
while (it->_index <= _output.bytes_written() && !_waiting_buffer.empty()) {
if (it->_index + it->_data.size() > s._index + s._data.size()) {
_output.write(it->_data.substr(_output.bytes_written() - it->_index));
}
_unassembled_bytes_size -= it->_data.size();
_waiting_buffer.erase(it++);
}
} else {
insert_buffer(s);
}
if (eof) {
_flag_eof = true;
_pos_eof = index + data.size();
}
if (_flag_eof && _output.bytes_written() == _pos_eof) {
_output.end_input();
}
}
size_t StreamReassembler::unassembled_bytes() const { return _unassembled_bytes_size; }
bool StreamReassembler::empty() const { return _unassembled_bytes_size == 0; }
思路在代码中已经很清楚了。
Lab 2: the TCP receiver
https://cs144.github.io/assignments/lab2.pdf
首先需要了解 seqno、absolute seqno、stream index 的区别:
| Sequence Numbers | Absolute Sequence Numbers | Stream Indices |
|---|---|---|
| Start at the ISN | Start at 0 | Start at 0 |
| Include SYN/FIN | Include SYN/FIN | Omit SYN/FIN |
| 32 bits, wrapping | 64 bits, non-wrapping | 64 bits, non-wrapping |
| “seqno” | “absolute seqno” | “stream index” |
PDF 上面有一个例子,例如 byte stream 中保存的数据为 string 为 cat,并且 SYN = 2^32 - 2,那么三者值如下:
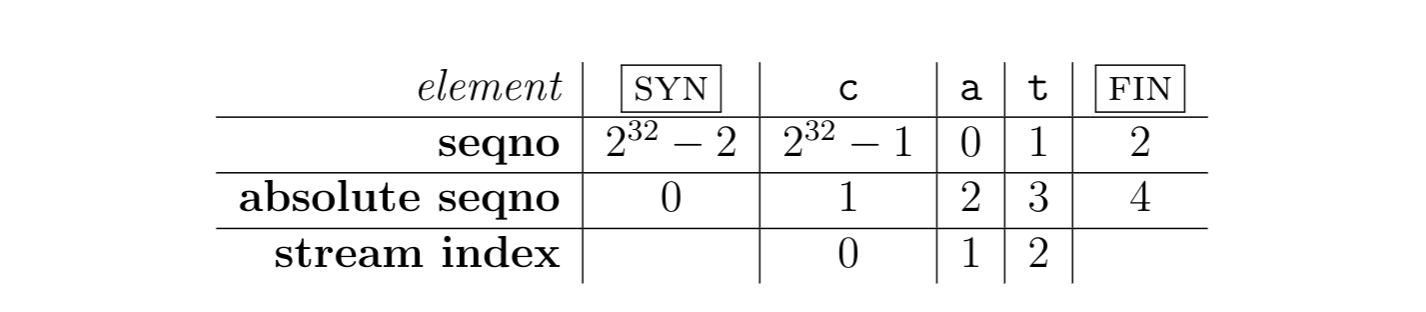
因为在 StreamReassembler 模块中使用的索引值是从 0 开始的,所以 TCP receiver 在重组子串之前,需要将从SYN+1 开始的 32 位索引还原成从 0 开始的 64 位索引。
第一个任务就是进行 32 位索引值和 64 位索引值的相互转换。
warp 是包装 64 位索引到 WrappingInt32 中,直接截取后 32 位加上 ISN 就可以了。
WrappingInt32 wrap(uint64_t n, WrappingInt32 isn) {
return WrappingInt32{static_cast<uint32_t>(n) + isn.raw_value()};
}
unwrap 实现(仿照网上实现写的):
uint64_t unwrap(WrappingInt32 n, WrappingInt32 isn, uint64_t checkpoint) {
uint64_t a = n.raw_value() - isn.raw_value();
if (checkpoint <= a)
return a;
uint64_t d = 1ul << 32, b, c;
b = (checkpoint - a) >> 32;
c = ((checkpoint - a) << 32) >> 32;
if (c < d / 2) {
return b * d + a;
}
return (b + 1) * d + a;
}
TCP receiver